
1. 需求分析

数据源来自于阿里巴巴提供的某年淘宝用户购买商品数据集,通过该数据进行大数据数仓的建设和开发分析,从以上几个维
度分别分析并将结果可视化(如上图)
| 文件名称 | 说明 | 包含特征 |
|---|---|---|
| user_info_format1.csv | 包含所有用户的信息 | id “唯一标识id”, age_range “年龄范围”,gender “性别 0女 1男 2保密” |
| user_log_format1.csv | 文件存放的是购买行为日志 | user_id,item_id,cat_id,seller_id, brand_id,time_stamp,action_type |
user_log_format1.csv 本数据集为用户的购买日志,即数据集的每一行表示一条用户购买行为,由user_id"买家id",item_id"产品id",cat_id"分类id",seller_id"卖家id",brand_id"品牌id",time_stamp"时间戳"和action_type"行为类型"组成,并以逗号分隔。关于数据集中每一列的详细描述如下:

2.创建Hive表
node1上启动hadoop集群:startha.sh(这个是一个脚本,可以对应hive专栏中查看)

node3上开启hive的客户端和服务端
[root@node3 ~]# hive --service metastore & # 开启服务端 [1] [root@node3 ~]# 2023-05-05 08:54:55: Starting Hive Metastore Server # 开启客户端 [root@node3 ~]# hive --hiveconf hive.cli.print.header==true which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/default/bin:/opt/zookeeper-3.5.7/bin:/opt/hadoop-3.1.3/bin:/opt/hadoop-3.1.3/sbin:/opt/hive-3.1.2/bin:/root/bin) Hive Session ID = 5cd5ecfb-203d-401b-86f5-eacd905bd2e5 Logging initialized using configuration in jar:file:/opt/hive-3.1.2/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Hive Session ID = f92b7d5f-8dc1-4c02-9cac-74b704c6eea4 hive> 创建hive库
hive> create database if not exists taobao; OK Time taken: 0.223 seconds hive> show databases; OK default hivedb1 taobao Time taken: 0.025 seconds, Fetched: 3 row(s) hive> use taobao; # 切换hive数据库 OK 创建hive数据表
创建用户信息表
create table if not exists to_user_info( id int comment "唯一表示id", age_range int comment "年龄范围", gender int comment "性别 0女 1男 2保密" ) row format delimited fields terminated by "," lines terminated by "\n"; hive> create table if not exists to_user_info( > id int comment "唯一表示id", > age_range int comment "年龄范围", > gender int comment "性别 0女 1男 2保密" > ) > row format delimited > fields terminated by "," > lines terminated by "\n"; OK Time taken: 0.746 seconds 创建用户行为日志表
create table if not exists to_user_log( user_id int comment "买家id", item_id int comment "产品id", cat_id int comment "类别id", seller_id int comment "卖家id", brand_id int comment "品牌id", time_stamp bigint comment "时间戳", action_type int ) row format delimited fields terminated by "," lines terminated by "\n" # 创建表 hive> create table if not exists to_user_log( > user_id int comment "买家id", > item_id int comment "产品id", > cat_id int comment "类别id", > seller_id int comment "卖家id", > brand_id int comment "品牌id", > time_stamp bigint comment "时间戳", > action_type int > ) > row format delimited > fields terminated by "," > lines terminated by "\n"; OK Time taken: 0.104 seconds hive> show tables; OK to_user_info to_user_log Time taken: 0.035 seconds, Fetched: 2 row(s) 传输csv文件到虚拟机中——传输后删除否则占用虚拟机内存

导入本地excel到hive表中
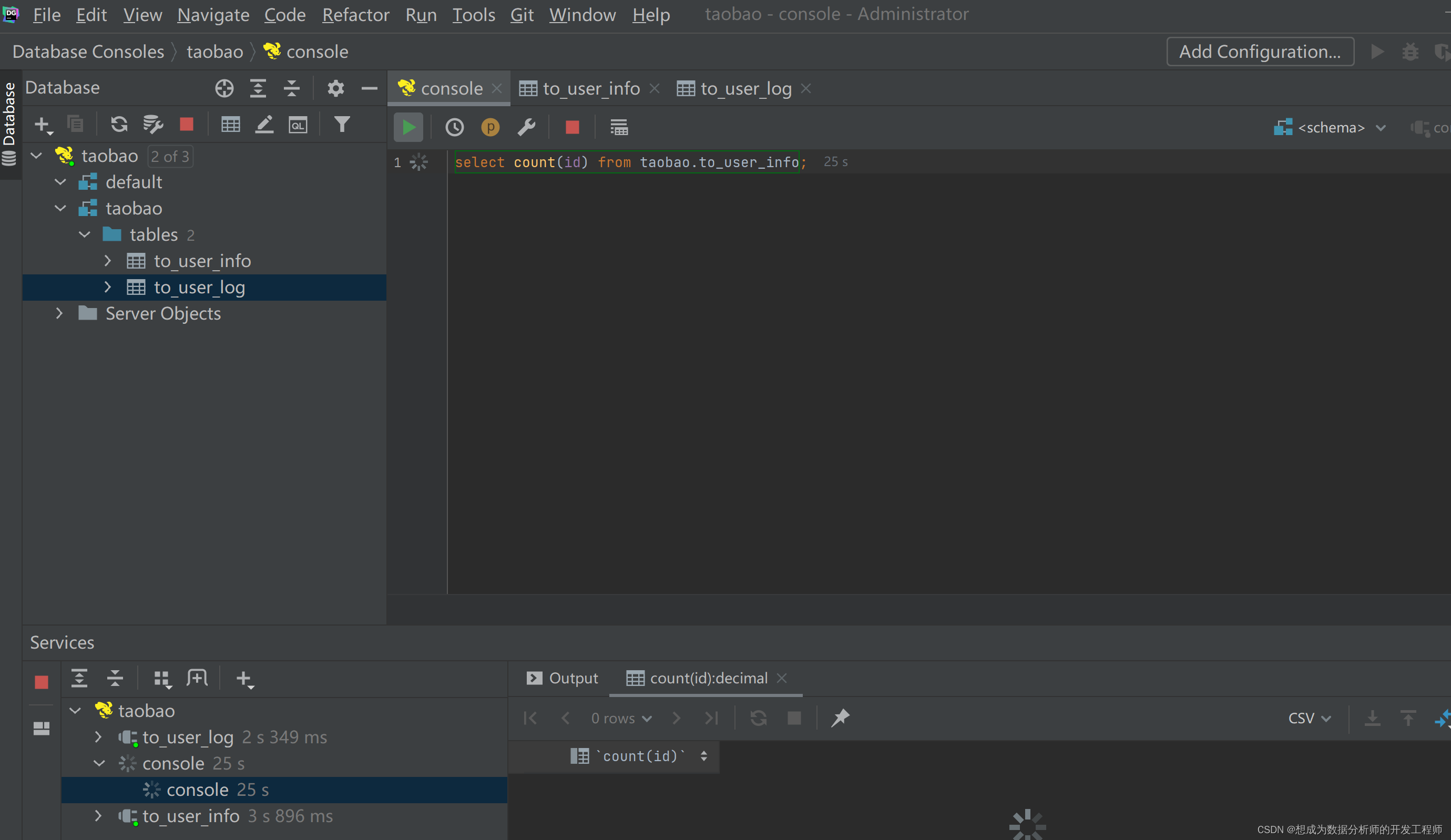
hive> load data local inpath '/root/user_info_format1.csv' into table to_user_info; Loading data to table taobao.to_user_info OK Time taken: 3.032 seconds hive> load data local inpath '/root/user_log_format1.csv' into table to_user_log; Loading data to table taobao.to_user_log OK Time taken: 42.481 seconds hive> select count(id) from taobao.to_user_info; OK 删除文件
[root@node3 ~]# rm -f user_info_format1.csv user_log_format1.csv [root@node3 ~]# ls anaconda-ks.cfg 此时,我们发现在虚拟机中直接写代码是非常不友好的,没有高亮显示、没有拼写错误提示。这时候我们就需要一个可视化的工具——DataGrip
3.DataGrip安装激活
DataGrip的功能就类似Navicat,对虚拟机上的hive数据库可视化。操控,查询等功能
数仓开发工具可选用DBeaver或者DataGrip。
下载网址:https://www.jetbrains.com/zh-cn/datagrip/download/other.html
将Datagrip安装到D:\devsoft\JetBrains\DataGrip22.2.1目录下。
将解压后的ja-netfilter拷贝到D:\devsoft\JetBrains下(以后不要动它)
进入 Datagrip 的安装目录 D:\devsoft\JetBrains\DataGrip22.2.1\bin 目录下,修改 datagrip64.exe.vmoptions 配置文件:
exe文件——选择好路径


移动激活成功教程文件夹到目标文件夹中

打开此文件

添加补丁路径

打开DataGrip

复制激活码

DataGrip2022密钥:
UQ99Q03MFY-eyJsaWNlbnNlSWQiOiJVUTk5UTAzTUZZIiwibGljZW5zZWVOYW1lIjoiZnV6emVzIGFsbHkiLCJhc3NpZ25lZU5hbWUiOiIiLCJhc3NpZ25lZUVtYWlsIjoiIiwibGljZW5zZVJlc3RyaWN0aW9uIjoiIiwiY2hlY2tDb25jdXJyZW50VXNlIjpmYWxzZSwicHJvZHVjdHMiOlt7ImNvZGUiOiJQREIiLCJmYWxsYmFja0RhdGUiOiIyMDIzLTA3LTAxIiwicGFpZFVwVG8iOiIyMDIzLTA3LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IkRCIiwiZmFsbGJhY2tEYXRlIjoiMjAyMy0wNy0wMSIsInBhaWRVcFRvIjoiMjAyMy0wNy0wMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUFNJIiwiZmFsbGJhY2tEYXRlIjoiMjAyMy0wNy0wMSIsInBhaWRVcFRvIjoiMjAyMy0wNy0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQV1MiLCJmYWxsYmFja0RhdGUiOiIyMDIzLTA3LTAxIiwicGFpZFVwVG8iOiIyMDIzLTA3LTAxIiwiZXh0ZW5kZWQiOnRydWV9XSwibWV0YWRhdGEiOiIwMTIwMjIwNzAxUFNBTjAwMDAwNSIsImhhc2giOiJUUklBTDotMjI1OTU1Njc5IiwiZ3JhY2VQZXJpb2REYXlzIjo3LCJhdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlLCJpc0F1dG9Qcm9sb25nYXRlZCI6ZmFsc2V9-d2YwlrEKsQxrYTT5V/oo6/vGvFxQoguCe2m55PfMJd7C2OWXzr3fRtOY4tp8OVv+UKK1gXMgpQx+zvZrrdgIQF8J3NBYIBek3W7RywlY93Eg4y56GAZu1V3+ER8U1hVvJiD0daS5TSgJKXp/dus6NY+qMgDekGd+ccd1DD8wW83GLqMjBi+rGxYnDwE/RzcScxfNfbBdE1AdUz+lOEq4RKfvuCxgjry+pD4gQE0nfAF1CK9UyCu+/FFNzKl5E7sCKh7ONfE2RWwXts3zOcV0m4E092QHZ2IB08VU7zYuvQta44uZfsMsuOx27FVq4R3RZsgdcFD+vJeW7tIXM97vaw==-MIIETDCCAjSgAwIBAgIBDTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVDDA1KZXRQcm9maWxlIENBMB4XDTIwMTAxOTA5MDU1M1oXDTIyMTAyMTA5MDU1M1owHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMDEwMTkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCUlaUFc1wf+CfY9wzFWEL2euKQ5nswqb57V8QZG7d7RoR6rwYUIXseTOAFq210oMEe++LCjzKDuqwDfsyhgDNTgZBPAaC4vUU2oy+XR+Fq8nBixWIsH668HeOnRK6RRhsr0rJzRB95aZ3EAPzBuQ2qPaNGm17pAX0Rd6MPRgjp75IWwI9eA6aMEdPQEVN7uyOtM5zSsjoj79Lbu1fjShOnQZuJcsV8tqnayeFkNzv2LTOlofU/Tbx502Ro073gGjoeRzNvrynAP03pL486P3KCAyiNPhDs2z8/COMrxRlZW5mfzo0xsK0dQGNH3UoG/9RVwHG4eS8LFpMTR9oetHZBAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQUJNoRIpb1hUHAk0foMSNM9MCEAv8wSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBABqRoNGxAQct9dQUFK8xqhiZaYPd30TlmCmSAaGJ0eBpvkVeqA2jGYhAQRqFiAlFC63JKvWvRZO1iRuWCEfUMkdqQ9VQPXziE/BlsOIgrL6RlJfuFcEZ8TK3syIfIGQZNCxYhLLUuet2HE6LJYPQ5c0jH4kDooRpcVZ4rBxNwddpctUO2te9UU5/FjhioZQsPvd92qOTsV+8Cyl2fvNhNKD1Uu9ff5AkVIQn4JU23ozdB/R5oUlebwaTE6WZNBs+TA/qPj+5/we9NH71WRB0hqUoLI2AKKyiPw++FtN4Su1vsdDlrAzDj9ILjpjJKA1ImuVcG329/WTYIKysZ1CWK3zATg9BeCUPAV1pQy8ToXOq+RSYen6winZ2OO93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXugOoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5zfhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZOEmH0nOnH/0onD 3.1 配置HiveServer2
DataGrip需要用到JDBC协议连接到Hive,需要配置HiveServer2。
若配置过直接跳到启动步骤开始
具体配置步骤:
关闭hive
[root@node3 ~]# fg hive --service metastore ^C[root@node3 ~]# ^C [root@node3 ~]# 关闭hadoop
[root@node1 ~]# stopha.sh # 之前文章写好的脚本 修改hive配置,支持hiveserver2启动
[root@node3 ~]# vim /opt/hive-3.1.2/conf/hive-site.xml 添加以下配置,在最后 <!-- 指定hiveserver2连接的host --> <property> <name>hive.server2.thrift.bind.host</name> <value>node3</value> </property> <!-- 指定hiveserver2连接的端口号 --> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> 修改core-site.xml
/opt/hadoop-3.1.3/etc/hadoop [root@node3 hadoop]# vim core-site.xml <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> 分发给所有节点
[root@node3 hadoop]# scp core-site.xml node1:`pwd` core-site.xml 100% 1550 689.9KB/s 00:00 [root@node3 hadoop]# scp core-site.xml node2:`pwd` core-site.xml 100% 1550 542.7KB/s 00:00 [root@node3 hadoop]# scp core-site.xml node4:`pwd` core-site.xml 启动hadoop集群
[root@node1 hadoop-3.1.3]# startha.sh ZooKeeper JMX enabled by default 启动hive
[root@node3 ~]# nohup hive --service metastore & [1] 69316 [root@node3 ~]# nohup: 忽略输入并把输出追加到"nohup.out" 启动hiveserver2
[root@node3 ~]# nohup hive --service hiveserver2 & [2] 69532 [root@node3 ~]# nohup: 忽略输入并把输出追加到"nohup.out" 连接hiveserver2
[root@node4 ~]# beeline -u jdbc:hive2://node3:10000 -n root -p 123 Connecting to jdbc:hive2://node3:10000 Connected to: Apache Hive (version 3.1.2) Driver: Hive JDBC (version 3.1.2) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 3.1.2 by Apache Hive 0: jdbc:hive2://node3:10000> 0: jdbc:hive2://node3:10000> show databases; +----------------+ | database_name | +----------------+ | default | | hivedb1 | | taobao | +----------------+ 3 rows selected (3.106 seconds) 3.2 DataGrip配置
打开DataGrip
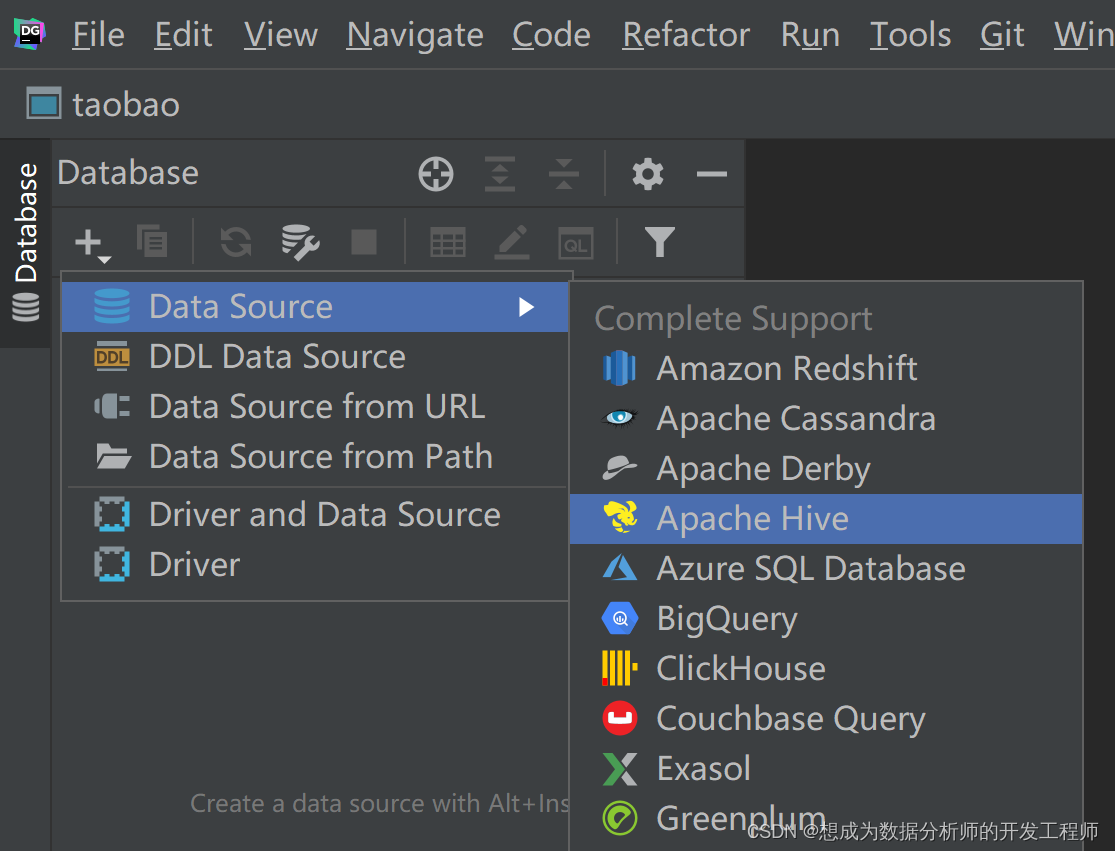
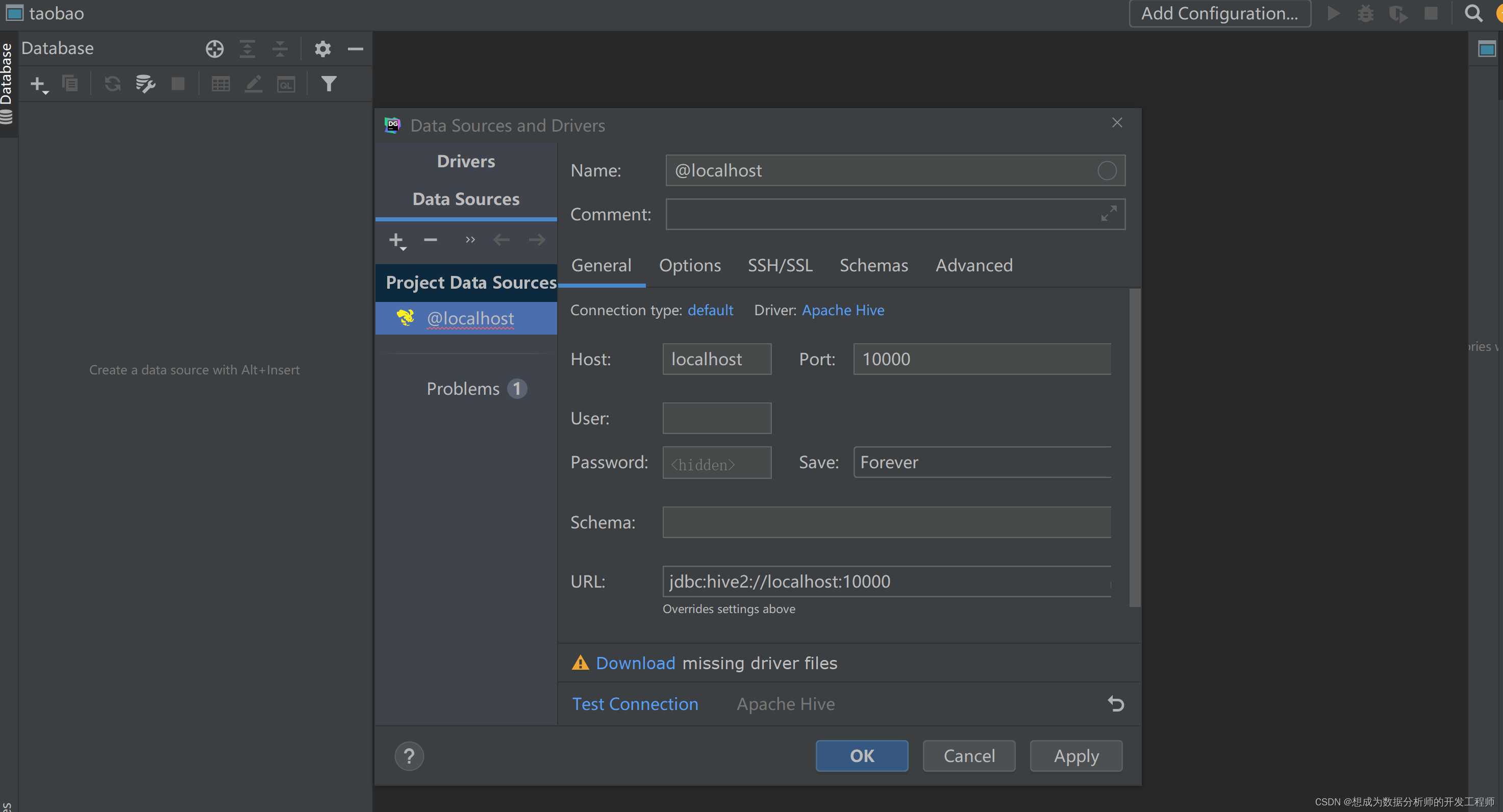
DownLoad下载
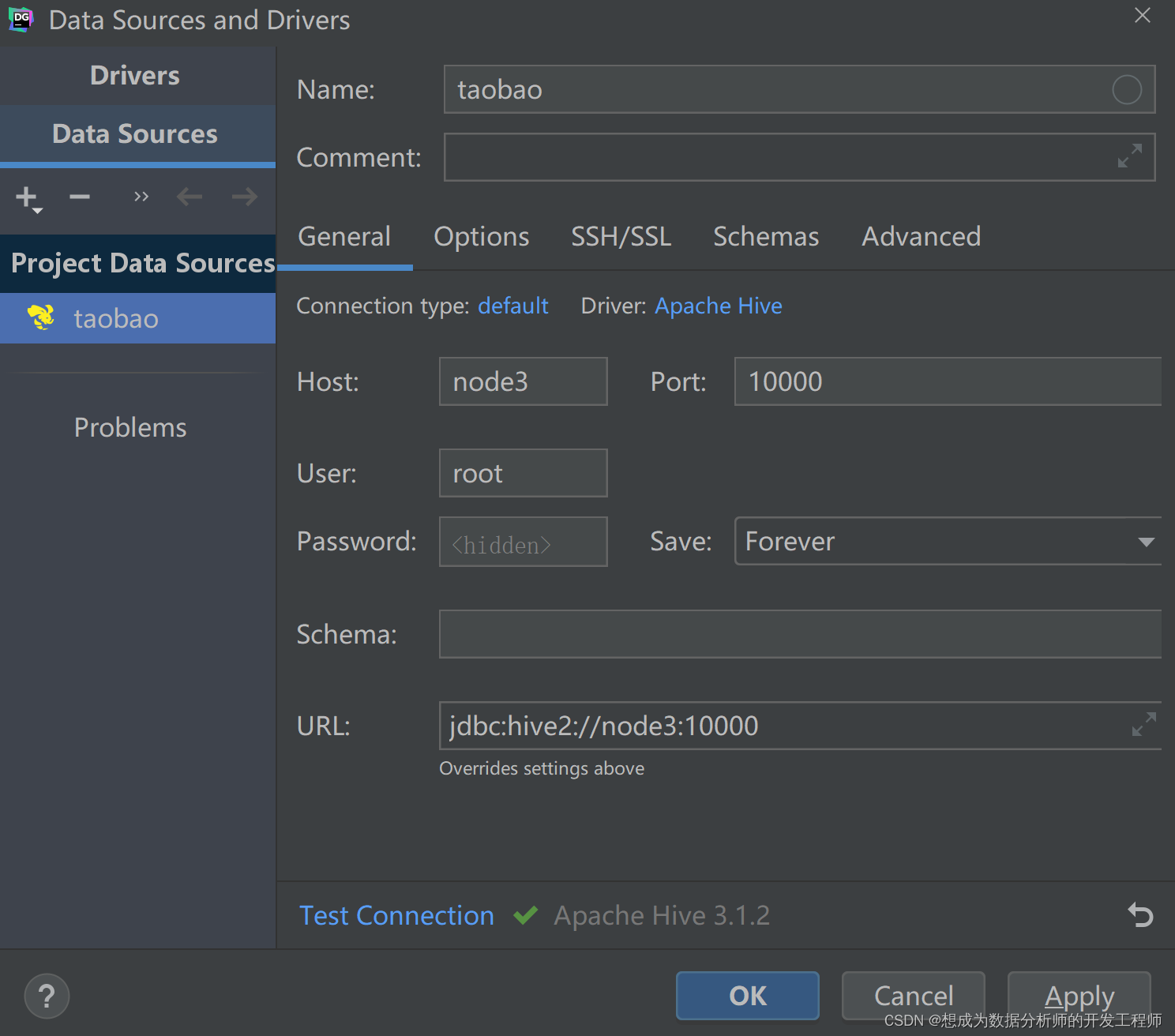
先Apply 然后OK
选择淘宝
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://sigusoft.com/datagrip/3210.html